Background
Designing and administering a SQL Server database doesn't only involve knowing how to break up your data into tables and define the relationships between them. You also need to know how to appropriately INDEX your database, as in knowing what indexing actually is and how it works.
The best metaphor to use when describing data storage in a SQL Server database is an old-fashioned paper book. I know it's an anachronism in 2025, so I hope you can follow along.
SQL Server data is stored in physical data blocks called Pages (you're starting to see why the book metaphor is apt) that are 8KB in size. If you've worked in SQL Server long enough, this number may be familiar to you.
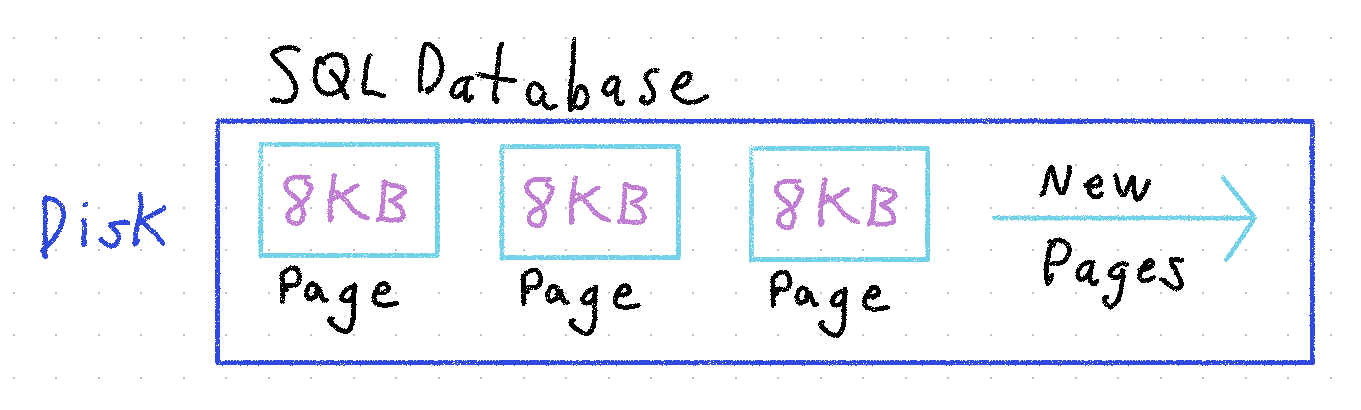
When you tell SQL Server to store some data, it looks at certain fields in that data (the Clustered Index) to figure out which page in the table, and which specific location on that page, is appropriate. It then checks the space left on that page to see if it can squeeze in your new data. If there's enough left, it writes the data. If not, it causes a Page Split. Too many Page Splits will kill your database performance. I'll talk more about Page Splits in the second part of this post.
Clustered Indexes
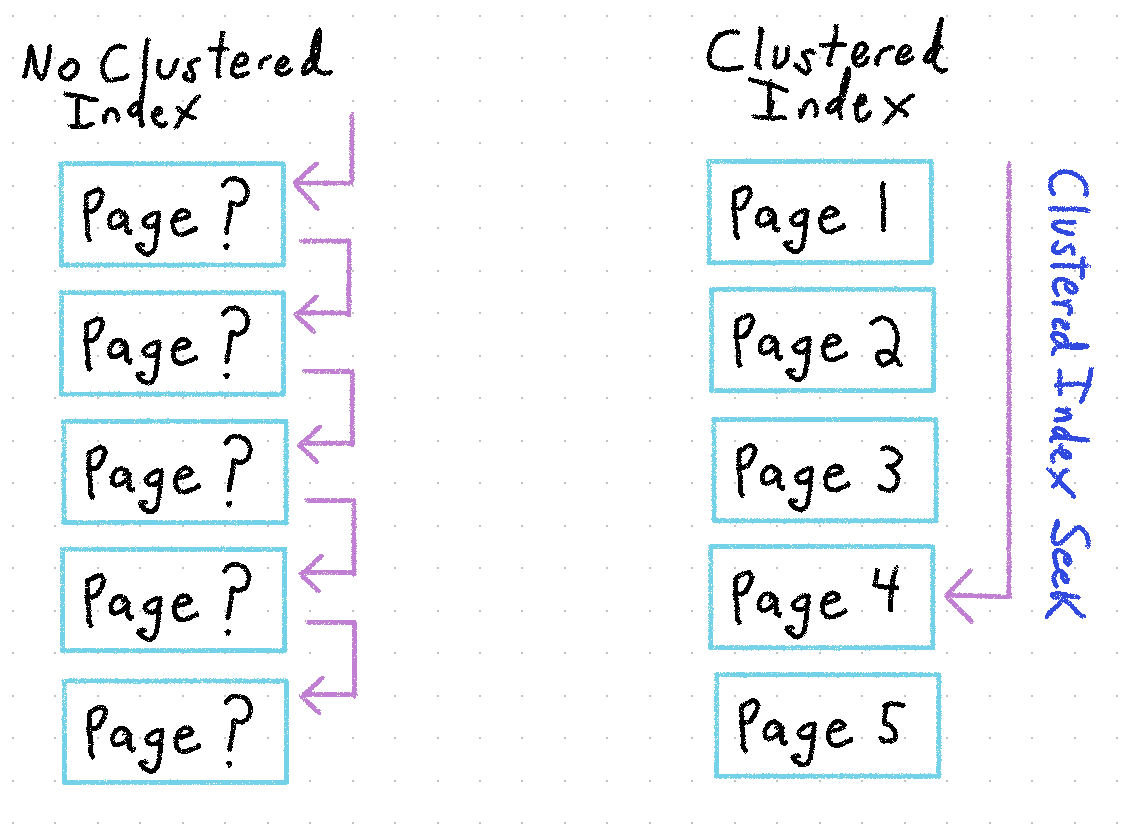
If you want to find some information in a book, the brute-force method is to read through every single page, starting from the first page, until you find what you're looking for. It can be very time-consuming for larger books with lots and lots of pages.
In SQL Server terminology, this is called a Full Table Scan, where every single row of data is scanned through and checked for your desired results. Much like reading through a book, this can be very resource- and time-consuming for large databases. It can also create a Table Lock which prevents any writes, blocking other processes and potentially causing system timeouts and crashes. The cascading failures can be quick and fatal.
The Phone Book's White Pages had a brilliant solution to this problem. People's phone listings were sorted alphabetically by LAST NAME, then FIRST NAME, so that the reader, knowing the sort order in advance, would be able to quickly scan through the pages to find the person they were looking for.
The equivalent concept in SQL Server is the Clustered Index, and each server can have exactly zero or one of them. Stored with your data, it defines the physical sort order of your data in the database, and provides an almost instantaneous way for the database engine to find what you're looking for. This is typically an artificial int identity ID value that's also the Primary Key, which is okay a lot of the time as long as you create appropriate Non-Clustered Indexes. But the Clustered Index and the Primary Key don't necessarily have to be the same. In some cases, you may want them to be different. I'll talk more about this in the second part of this post.
Tables with no Clustered Index are called Heap Tables. They can be useful when you need extremely high write performance, but data is always appended to the end and reading from them is a very slow process.
Non-Clustered Indexes
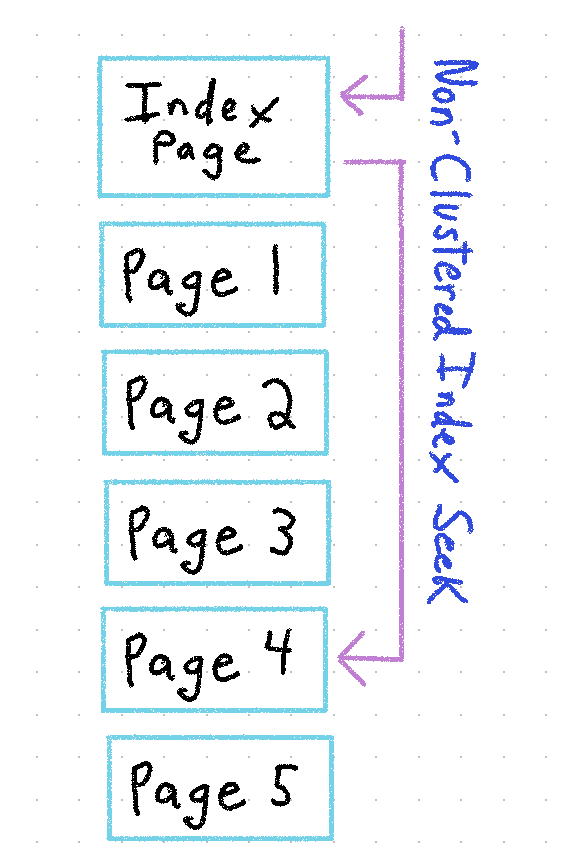
Some pages store actual data content, while others store metadata about the database. For example, Non-Clustered Indexes.
If the Clustered Index defines the physical sort order of your data, the Non-Clustered Index provides pointers to the physical location of your data based on some other value. A Phone Book that's sorted by LAST NAME, FIRST NAME may also have separate pages with lists of AREA CODES, CITIES, or ZIP CODES. These lists show the corresponding page numbers of matches in the book, drastically increasing your lookup speed, because without them you would need to run a Full Table Scan to find what you're looking for.
Non-Clustered Indexes operate in the same fashion. You define which field(s) on the table should be included in each index, and the query optimizer will (usually) determine the appropriate index(es) to use in each query, based on the query conditions.
Indexing Pros:
- Proper indexing will significantly improve performance when querying larger data sets.
- Proper indexing will increase system stability with fewer resources used and fewer blocking events.
- Proper indexing will reduce server downtime due to database maintenance.
Indexing Cons:
-
Any data update on a table triggers the associated index(es) to also be updated within the transaction, requiring additional processing time and server resources. Over-indexing a table will significantly degrade the performance of write operations.
-
Indexes require additional space within the database, increasing the size of the database beyond just the data itself. You need to plan for this or you may run into space availability problems later on.
-
Improperly-defined indexes can become fragmented over time and performance will be slowed. They need to be defragmented (like we used to manually defrag our hard drives decades ago) or rebuilt periodically to be fixed.
Index Considerations
Stay tuned for the second part of this post, in which I discuss the best practice considerations around HOW to index your database.